Innovate Without Trying: Make New-doing The New Normal
Innovation isn't a thing—it's a doing. Specifically, it's an agentic practice that takes invention from new to normal.
The Verbness Of Innovation: Doing The New
Joseph Schumpeter describes innovation as “the doing of new things or the doing of things-already-being-done in new ways”. The new-doers, then, invest time and effort in doing things in ways that are new to them.
But why go through all that trouble? Precisely because they have jobs that need to be done—and they have doubts about their current practices. Their situated discontent prompts new-doing, because things could be better.
Schumpeter's Shift
All innovation comes down to this Schumpeterian shift: a new doing of things, adopted as normal practice by the people ‘doing the new’. Only once enough new-doers adopt the new doing into their workflows (forming Everett Rogers' early majority) does it cross the chasm (as Geoffrey Moore would have it) and earn the title “innovation”.

Adoption is the quantum of innovation. By doing the new, people become agents of change and growth. Adoptions—microinnovations, really—sum to macroeconomic whirlwinds. This is Schumpeter‘s gale of creative destruction and Clayton Christensen's disruptive innovation in operation. A tiny shift in practice can cause a Butterfly Effect—via Bak's self-organized criticality (or any other term for cascade phenomena).
How can companies accelerate the New-Ideas-To-New-Normal process?
Agency engineering: operationalize Kahneman's System 2 and turn good intentions into architecture.
Top-down? Bottom-up? There's a third option that breaks the dichotomy: agent-forward!
Innovation is not a hero‘s quest. Trying to recruit mythical heroes—the self-starters, the intrapreneurs, the innovators—is not the answer, nor a sustainable strategy. Thing is, “new-doer” is not a job description for a rare breed of person. They're ordinary...
- thinkers that caution,
- planners that forecast, and
- doers that get shit done
but with the agency to make a difference—to do the new.

Agency means purpose, mastery, and autonomy. Daniel Pink argues that this trinity is what motivates us as humans and as agents-of-a-company in the first place. But motivation alone isn't enough. This trinity must be encoded, embedded, embodied in workflows—to structurally empower teams to do the new.
Without agency, there is no new-doing. No adoption of new doings. No innovation. Just going through the motions—repeating old mistakes. Again and again. That light at the end of the tunnel? Hope? No, it's an oncoming release train—the sound of inevitability. No future, as the Sex Pistols commented on organizational command-and-control schemas.
But punk's not dead. Now listen to Refused's The Shape Of Punk To Come.
AGENCY makes new-doing automatic
Whether laziness or necessity is the mother of invention is irrelevant. Point is, humans—left to their own devices—will always come up with new ideas, new ways to do things, and new things to do. New-doing is the natural state of the human animal. Human history, including human evolution, is a testament to this statement. Our invention and subsequent adoption of fire and flint (e.g., knives)—to pick two innovations from pre-history—has reshaped our very jaws and digestive systems.
To pick a very recent and tragicomic development: Smartphone Neck causing growth of bone spurs.
BOOSTS make new-doings effective
Now, composing teams for agency—and we say teams, because getting anything worthwhile done in a way that makes it worth the while takes a team effort—does make new-doing automatic. But not necessarily effective.
For your new-doing teams to be effective, you need to equip them with boosts.
All our space missions must be boosted to Low Earth Orbit before they can ‘boldly go’ explore space. Earth's gravity well is a steep climb, much like the inertia of organizational systems hold new-doers back. Your new-doers are busy. They have what Christensen calls Jobs-To-Be-Done—preferably yesterday. Unsurprisingly, they are reaching for—possibly aching for—utilities, services, or self-services that they can employ to boost their new-doing. If we put this in terms of Team Topologies by Skelton & Pais, we can paint their stream-aligned teams as new-doing teams and their platform teams as boost-builders.
The agent-forward organization requires two core capabilities.
- New-doing depends on agency engineering
- Boosting depends on platform engineering (e.g., infra-as-code for Data×AI boosts)
A boost becomes a product in Christensen's JTBD sense: a thing-to-be-employed by people doing the jobs-to-be-done.

Boost—for easier and faster scaling of new doings
Boosts don't grant agency. They are there to amplify new-doer agency— like a Marshall stack amplifies a Stratocaster to make some noise! Boosts lower the cognitive, organizational, and technical thresholds of new-doing—and remove blockers. Boosts are capital assets: not just operational enablers, but modular infrastructure for scaling innovation.
Your portfolio of boosts constitutes innovation capital. In biology, a keystone species is one whose actions have an outsized effect on the whole ecosystem. Boosts work the same way. Get them into play, and new-doing and adoption of new doings becomes easier and faster. Ignore them, and you'll wonder why nothing scales.
Time-To-Normal Measures Speed Of Innovation
With lower thresholds and fewer blockers, new-doing teams can shorten the New-To-Normal cycle. The outcome? Improved Time-To-Normal. We talk about about speed of innovation—in the abstract. In practice, the only viable metric for innovation is Time-To-Normal. Because innovation doesn’t happen when an idea is born—that's mere invention. Innovation happens when the new becomes the normal.
At the end of the day, measure your Time-To-Normal—because your innovation performance hinges on Schumpeter's Shift.
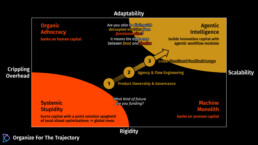
Bonus Material: Why Innovation Turns Into Theatre
Innovation is hard. Not because people resist change, because they don't—the natural state of the human animal is new-doing. Innovation is hard because systems resist agency. Systemic stupidity is the default outcome of ignoring agentic intelligence.

My PhD in the sociology of innovation and culture starts with this age-old observation by Arthur Stinchcombe: “Organizations, once established, tend not to change". No less true, 60 years later. Orgs don't change because change efforts tend to become innovation theatre—exercises in smoke-and-mirrors that make little difference, leaving even less that sticks.
Innovation theatre isn’t a failure of imagination. If it's one thing humans are good at, it's imagining the not-real-but-should be: we have libraries full of fanciful fiction. Innovation theatre is the logical outcome of systems inadvertently optimized to eliminate new-doing.
POSIWID: Because Implementation Has Unintended Consequences
Stafford Beer put it plainly: the "Purpose Of a System Is What It Does”. Not what it says it does. Not what its makers intended. What it does.
Look at your company’s incentives, controls, and workflows. If they systematically reward orderliness, silence doubt, and prioritize throughput over thought—then your system is like a watchmaker skeletonizing the clockwork for a timepiece: it is doing precision, the antithesis of innovation.
To mix metaphors: if the trains are running like clockwork, the system is working. Who cares if they’re going to the right stations or not? That’s the passengers’ problem.
Don't try any funny business. Most—if not all—companies go to great lengths to throttle the agency of their people in the sacred name of Business As Usual (BAU). Not intentionally, mind you. Agency-throttling is a systemic by-product of standardization and Minimization of Agent Deviation—the MAD heuristic that orgs default to. It doesn’t care about growth opportunities. It cares about command, control, and compliance. And that shit don't innovate.
Dismiss the doubts—the what-ifs, the why-nots—and innovation dies. Not with a bang but with a whimper, as discontent withers into apathy.
‘Business As Usual’ Comes With Blind Spots Baked In
It’s not just that BAU resists change—it resists seeing that change is even needed.
- Margaret Wheatley reminded us, “To name is to make visible”
- Daniel Kahneman taught us, “What you see is all there is”
- George Box warned, “It’s inappropriate to be worried about mice when there are tigers abroad.”
Most orgs spotlight the mice—and blind themselves to the tigers in the shadows: the unintended consequences of well-meant decisions. That’s the problem with blind spots—they’re hard to even notice, let alone address.
Let’s name the big one. As long as cost reduction trumps new-doing in executive priority, any deviation–mistake–error will register as a cost-to-reduce long before it can register as an opportunity-to-grow. That’s not just an operational glitch, it’s a cultural pathology.
Culture—In Operation
Culture isn’t fluff. It's not core values, soft skills, and wishful thinking.
Culture is the practices and policies embodied by your agents. Culture is “the collective programming of the mind”, as Geert Hofstede put it. Culture is the shared programs running as the mindware of your agents: embodied practices and policies encoded in workflows. Culture is your intellectual seed capital.
Innovation Culture: Reprogram The Organization, One Boost At A Time
If you want innovation, you have to reprogram the system—boost by boost. In practice, this starts withreprogramming the minds of managers and executives. They must understand that the gravitational pull of BAU stops any new-doing effort from getting off the ground. Else, they’ll keep demanding “transformation” while reinforcing the very system that makes it impossible.
Want your org to innovate? Stop punishing agency. Start building the infrastructure—the boosts—that make 'doing the new' easier, faster, and normal.
Want to kick-start an innovation culture? Innovation starts with agency. It scales with boosts. Schumpeter’s Shift is how to make new-doing the new normal.

FFSS Data Patterns For Better Intelligence—Human Or Artificial
AI development should abandon schema-first models, and directed acyclic graphs in particular, as the backbone for its entity models—to embrace Feedback-First, Schema-Second semiotics (FFSS) that encode feedback loops as foundational data patterns. This enables...
- Schema-second data patterns that don’t box you in like schema-first databases or rob you of structure like schema-less ones
- Fluid ontologies and knowledge graphs that emerge and evolve with new understanding
- Agile data–decision workflows that scale smoothly
- Double-loop reinforcement learning for Agentic AI
The AI challenge: not neural circuits, but rewiring them
The challenge for AI is not about replicating the neural circuits of animal wetware with man-made circuitry. The challenge is emulating the evolving synaptic network: the feedback loops signalling neurons to form new circuits or grow new neurons. Adaptation, learning, and cognition depends on synaptic re-networking where neural circuits modify other circuits. To emulate this neuroplasticity, AI must be able to encode feedback loops as data patterns—including loops that operate on other loops, i.e., code patterns. This demands a Feedback-First, Schema-Second (FFSS for short) pattern language that can treat schemas as any other pattern.
Incidentally, this lands us in semiotics, the science of patterns and pattern languages, and the budding field of biosemiotics. In brief, semiotic processes involve metaprogramming—patterns that interoperate with and operate on other patterns.
AI has an entity model problem
Real-world adaptive systems—like brains, bacteria, and human sciences—are inherently FFSS. They continuously create and discard schemas in response to feedback—new data and possible anomalies. Brains rewire synaptic networks. Bacteria edit genome–proteome ‘workflows’. Science revises theories and models. If we want to build actual learning machines and cognition engines, we should make feedback loops first-class citizens in our entity models—perhaps even the foundational primitives.
Modelling brains as directed acyclic graphs (DAG) in any form is an anti-pattern. DAG models commit ontological violence on real-world systems by severing the very cycles and loops that make adaptation and learning possible. The acyclic chains of DAGs yield hierarchical or sequential rigidity. They cannot deal with evolving patterns that refuse to behave, that continuously adjust to feedback and obsolete old schemas—or the compounding effects of that, such as emergent behaviours.
Alternatives to 'DAG logic' databases
Most databases and knowledge management systems suffer from the flaws of ‘DAG logic.’ They are either schema-first (think SQL or RDF)—or they go schema-less to escape rigidity (think NoSQL). So far, the author has identified only two available pattern/query languages that...
- support cyclic data patterns(‘feedback-first’) and
- treat schemas as data(‘schema-second’):
The Datomic superset of Datalog and the Cypher family of graph query languages (e.g., Neo4j). Datomic embraces the FFSS approach, while Cypher at least allows it.
Thinking, learning, doubting: semiotic metaprogramming
FFSS semiotics paves the way for AI systems that can doubt—the limit case for intelligent behaviour. Ultimately, learning is about re-encoding data and data patterns recursively in response to feedback. This includes operational schemas: practices, policies, programs, and paradigms. In practice, learning requires that agents, whether human or artificial, can CRUD the RAGs that govern their behaviour—including their CRUD capabilities. In two words: semiotic metaprogramming.
This goes double for Agentic AI. Having AI agents in agentic workflows necessitates shared databases and collaborative data patterns—not least for them/it to iteratively internalize input/feedback from other agents in other workflows.

Bright Lights Create Blind Spots: Managing The Sociotechnics of Data & AI
You want to boost productivity by leveraging AI and AI agents, Data Mesh, or advanced analytics (BI-DS-ML). Everybody does.
But that requires a shift in how you manage your operations. It's never about the tech. It's always about sociotechnical practices. Obsessing over the 'technical' parts while ignoring the 'socio' parts and the sociotechnical dynamics is a recipe for disaster in three dangerously easy steps.
- Blindly Chase Technology Without StrategyAdoption of data-driven and AI-boosted ways of working requires managers to design and operate sociotechnical systems
- Underestimate the Sociotechnical QuagmireThe risk of embedding fateful blind spots within these systems borders on certainty
- Stick to Outdated Management ModelsManagement blind spots, such as short-termism or tech solutionism, can ruin a company
Management blind spots litters history with cautionary tales
Technology does not make or break a business. It's the blind spots, the inability to see the errors of our ways, that kills companies. Consider Kodak and Facit. They collapsed despite being innovators and early adopters of the tech that killed their business. Blockbuster, Nokia, and Sears? They suffered from blind spots that left diminishing returns and vicious circles in their wake.
The idiom "the floggings will continue until morale improves" is meant to be satire. In Sears' case, the slogan for their decline was "cost-cutting will continue until sales improve". A 'solution' that worsens the problem it is supposed to solve, also known as the cobra effect, is an amusing kind of poetic justice when it happens to others. It's less funny when you inadvertently release the cobras into your own company.
And then we have scandals like Well's Fargo (false accounts), Enron (financial misconduct), and Volkswagen (emissions). Or actual disasters like Union Carbide in India. Blind spots that led to crime-inducing perverse incentives and organisational pathologies.
Blind spots hide our mistakes
Blind spots makes us ignore the errors of our ways by hiding our mistakes from our perception. Management blind spots are system by-products that mask or obscure undesirable consequences, thereby encouraging or reinforcing counter-productive practices in operations. Managment blind spots are depressingly common, for two reasons.
- Implementing reinforcement learning loops is part of a manager's job
- The rule of Merton's "Law of Unintended Consequences" is absolute
Which is a polite way of saying that organisations are functionally stupid. In fact, Alvesson & Spicer's concept of functional stupidity [*] in organisations highlights the problem that the language and semantics of management is ill-equipped to deal with the blind spots it produces. An outside view, ideally transdisciplinary, is probably necessary to pre-empt the dangers of grouphthink and exformation.
[*] See Alvesson & Spicer (2012), "A Stupidity-Based Theory of Organizations", Journal of Management Studies 49:7
Three heuristics for combatting management blind spots
In the Lord of the Rings, Galadriel gives Frodo a crystal phial in which the Light of Eärendil is captured and says "may it be a light to you in dark places when all other lights go out". In the here-and-now, business environments are turning increasingly dark: more volatile, uncertain, complex, and ambiguous (VUCA). Managers are in dire need of Eärendil's Light to illuminate their path to success.
Below, we describe three vital heuristics for reducing the risk of blind spots turning your Data or AI initiatives into a hot mess and for increasing your chances of achieving Data-AI-Ready Management. We believe they will still shine when all other lights go out in VUCA places.
- Companies, organisations, and operations are people
- They are also sociotechnical systems
- Kahneman's principle of What You See Is All There Is
We resort to heuristics to cope with complexity
Why 'heuristics'? Organising and operating a business is an optimisation problem that just becomes more complex and non-linear the closer you look. There are no optimal solutions, so we must rely on heuristics (simplifications, approximations) as guardrails to deal or cope with the problem, to set our priorities and our approach. While we named our own species homo sapiens, that name is aspirational at best. We are boundedly rational creatures, satisficers by nature. So, when it comes to management, heuristics is as good as it ever gets.
Organisations are people
Mary Parker Follett, the mother of modern management, said that management is the art of getting things done through people. This perspective is essential. Whatever else a company might be, it is embodied by people that are busy doing their jobs. This includes the managers, being busy making sure that others do and can do their jobs. Patrick Hoverstadt provides a simple summary of what managers do.
At its core, the purpose of management is very simple, it is to do two things: firstly to decide what needs to happen, and secondly to ensure that what should happen does actually happen. [from The Fractal Organization]
All systems nominal — managers maintain business as usual
If we rephrase Hoverstadt, a manager's job is making sure that their part of the organisation and the people in it are working and behaving as intended. In short, managers maintain business as usual (BAU). And they need to decide what that means in practice, in terms of organising and operating the work and the people doing the work. The very ability of the operations they manage to keep on working and behaving as intended hangs in the balance.
Our main message here is that the art of getting things done through people should explicitly involve encouraging and nudging people towards productive behaviours and away from the other type. This includes the managers. Because management constitutes reinforcement learning loops for everyone involved, regardless of manager awareness of this fact. People will form ways of working and of thinking in response to both the explicit and the implicit messages that managers send, regardless of whether or not the managers intend or even understand the messages sent.
Learning by doing
The usual meaning of learning by doing is learning to do something by trying to do it; learning on purpose. But we also learn things incidentally, unintentionally, and automatically. By doing, we learn things. The results and effects of doing something is data we crunch for future decision-making and action-taking. This happens regardless of whether we are aware of it or not. Kahneman talks about System 1, the parts of the brain's operations that are largely unconscious. System 1 is responsible for maintaining and updating our causal models of how the world works, in part or in full, informing us how to behave and respond in any given situation, depending on its "fast-thinking" perception of the situation. Stimulus and response. Cause and effect. Whether we like it or not, we become part of lots of different feedback loops [*] simply by doing our jobs or living our lives.
[*] The feedback loop is the core idea of cybernetics: an iterative process where actions lead to outcomes which are then evaluated and used to inform future actions. In fact, the concept of feedback loops originates from this discipline.
A light in dark places: double the feedback loops
Tradition decrees that managers send and the managed receive. Managers should break this vicious circle by doubling up on the feedback loops they create. The art of getting things done through people places the managers and the managed in reciprocal relations where both are both senders and receivers. The "people" can only get their things done through their managers. This implies servant leadership.
Ultimately, managers lead by example. The only behaviours you can hope to reinforce are your own; managers set the standard. If you don't care about blind spots, no-one will.
Organisations are sociotechnical systems
Reinforcement learning is just manager-designed feedback loops that 'teach' organisational behaviour. Fundamentally, managers design and operate multiple sociotechnical systems [*] of incentives and regulations, carrots and sticks, dos and don'ts. The important part of these systems are the sociotechnical practices they institute and reinforce for operations and for themselves. The least 'technical' and most 'socio' of management systems is direct supervision, leading by example, and coaching. This makes managers participant observers in agent-based models of their own making.
[*] We must note that system semantics are dangerous. Thinking of something as a system conjures up the image of something that we can neatly define and cleanly separate from other systems. In reality, systems are fractal things; any system is part of other systems. Systems Thinking is necessarily recursive. According to Peter Senge, it’s “a framework for seeing interrelationships rather than things, for seeing patterns rather than static snapshots. It is a set of general principles spanning fields as diverse as physical and social sciences, engineering and management” [from The Fifth Discipline].
Sociotechnical systems are made up of agent-to-agent interfaces
Generally speaking, the full complexity of a sociotechnical system cannot be adequately captured as a single system. Instead, we must direct our attention to the agents, the people the company employs to do things for the company. This includes the managers. The agents and their sociotechnical practices give rise to a plurality of systems. Lots of interfaces and institutions emerge [*] from the agent-agent interactions and relations that occurs as part of agents simply doing their jobs, minding their own business. Ultimately, any company, organisation, or unit (and its operations) is embodied by a mesh network of agents orchestrated by the managers. Organisations should be seen as agent-based models.
[*] See for instance Schelling's book Micromotives and Macrobehaviour. His model of unintended segregation illuminates how small decisions can compound to large-scale effects.
Preoccupation with the 'technics' of management produces blind spots!
As soon as managers add processes and tech for KPIs or OKRs, for reward mechanisms and performance reviews, and for monitoring in general, the systems get technical quite rapidly. This does not change the fact that managers orchestrate their agent-based models. But manager preoccupation with the technical parts of their systems can very well hide or mask the agent-based nature of operations (the 'socio' part). Hence, this preoccupation becomes a blind spot. Never forget that organisations are people, that your organisation is a mesh network of agents!
A light in dark places: management is a technology
Tech exists to serve the users. Sociotechnical systems are never about the tech, but the use of it. It's always about the users, their usages, and their value-in-use. Tech has a purpose: to boost their sociotechnical practices and their productivity with regards to some utility they enjoy.
In seeing organisations as sociotechnical systems, we must see management as the technology that operations use to boost their productivity. To root out management blind spots, we must see the management 'system' as the tech being used.
"What You See Is All There Is"
Managing the sociotechnical practices of an operation is itself a sociotechnical practice. Ideally, management as a practice boosts operational effectiveness. At the very least, management should ensure that operations stay on course. To make a nautical analogy, management fails when system blind spots shift the heading of the operations-as-a-ship, making it veer off course. In other words, management fails when it nudges or pushes agents in either operations and management into unintended ways of working. Or both.
No sane person would ever willingly design or adopt self-sabotaging practices. We can use Kahneman's principle of What You See Is All There Is (WYSIATI) to understand why we do it anyway. The immediate and direct effects of an incentive mechanism or reward system can (and should be) beneficial; this expectation is why we implement them in the first place. However, the loop can also have indirect effects that are not beneficial, encouraging behaviours that are undesirable by nudging people into unintended ways of working. The "imperious immediacy of interest" [*] in the desired effects can burn so brightly that it blinds us to the undesirable 'by-products' of the loop. Bright lights create blind spots. Because bright lights make it difficult to see anything else.
[*] Merton's third source of unintended consequences, after ignorance and error.
All models are wrong (but some are useful)
Statistician George Box observed that all models are wrong, but that some are useful. To get some utility out of a model, we must be "alert to what is importantly wrong" with a model because "it is inappropriate to be concerned about safety from mice when there are tigers abroad". This informs any model, quantitative and qualitative, such as organisational heuristics — our sociotechnical practices, our ways of working, and our ways of thinking about our ways of working (business ontologies). Blind spots makes us not look for tigers.
Box Thinking applies to Box's own statement and this article. Box Thinking certainly omits important epistemological complications, but it is supremely useful. This article is wrong in reducing organisations to mesh network of agents, but we are pretty sure it's the most productive perspective when it comes to turning tech into growth opportunities. Or at least when it comes to reducing the risk of crippling blind spots.
A light in dark places: 'You Are Wrong But You Can Be Useful'
Blind spots are insidious. Cognitive biases are part and parcel to our ways of thinking, which makes it difficult to use our thinking to combat them. In precisely the way, organisational blind spots make it difficult to organise them away. Good scientists learn Box Thinking or methodic doubt as a practice. While we did posit managers as participant observers of the 'models' they create, adding Box Thinking to the already hefty burden on managers would be unreasonable. But the light version of it — entertaining the notion that you are wrong, seeking outside views on things, and mulling it over — is reasonable. Which can be summarised as the principle of You Are Wrong But You Can Be Useful (URRBYCBU).
Illuminating the Sociotechnical Path
Steering through (or at least coping with) the sociotechnical complexity of melding data, AI, and human systems is not easy. The trilogy of "A Light in Dark Places" tries to distill open-ended heuristics for making decisions with less regrettable consequences. Recognizing and addressing the interplay between 'socio' and 'technical' aspects is not optional; it's the keystone of Data-AI-Ready Managementin VUCA environments, letting the arches of your sociotechnical systems bear weight.
Doubt is your searchlight
Blind spots are the Achilles' heel of any system. The bounds on human rationality make blind spots inevitable and numerous. The only thing we can do is to try to find them. Every blind spot dealt with clears the path to the future. So, embrace doubt! Entertain the notions
- That you are wrong but can learn to be useful and
- That your management model is a work in progress.
You are a service provider
Tech should amplify human capabilities. The sociotechnics of Data & AI reframe management as one technology among others used by operations. The people you manage depend on you getting things done so they can get their things done. They are the ones doing the heavy lifting.
About the Authors
At DAIRDUX, our busness is to help you understand the sociotechnics of Data & AI. We cannot in good conscience use Box's metaphor and say that we help you hunt critically endangered felines. But we do help you
- Root out blind spots
- Boost the productivity of your operations
- Turn Data & AI into growth opportunities

Productisation of Data and Teams
Common perspectives on productisation
In the ever-evolving landscape of product development and management, the concept of productisation stands out as a multifaceted process pivotal to transforming ideas into market-ready solutions. It simply means turning something that is not a product into a product, which is quite different from producingit.
Productisation is commonly approached through various lenses (such as process, revenue, capability, and mindset), each offering a unique perspective on turning internal processes or solutions into commercially viable products. This encompasses not only the initial phase of the product lifecycle, including discovery and design thinking, but also the monetization of existing solutions and the continuous adaptation to remain relevant in a changing market. Let's illustrate the four mentioned perspectives.
- Process: Productisation as the initial phase in the product lifecycle, encompassing product discovery and the adoption of design thinking methodologies. This stage is critical for identifying user needs and developing a viable product concept. Design Thinking.
- Revenue: Productisation as a means to monetise existing internal processes or solutions by offering them as products to external customers facing similar challenges. This represents a strategic shift from internal optimisation to external service provision.
- Capability: Productisation as a core competency that organizations must continuously and iteratively engage in to adapt and remain relevant within a rapidly changing market environment. This underscores the importance of innovation and responsiveness to evolving customer needs.
- Mindset: Productisation as a mindset shift towards a "capitalisation imperative", where organizations and individuals begin to view and evaluate their actions and potential offerings through the lens of product potential. This involves a strategic approach to thinking about services, processes, or intellectual properties as potential products. Product Thinking.
Productisation is about decoupling monolithic designs into modular designs
Fundamentally, productisation is an organisational concept that champions the shift from monolithic to modular designs through decoupling. This means deconstructing, reframing, or refactoring a 'product' into stand-alone and composable 'products' with high cohesion and low coupling, none of which were products before. Together they not only serve the purpose of the original 'product' with improved cost-effectiveness (lower coordination and maintenance costs) but also open up new offerings. This transition is essential for fostering flexibility, scalability, and innovation within an organization, breaking down complex systems into manageable, independent, composable, meshable components. It allows for cleanly separating concerns to different teams, each focusing on productising different things, thereby enhancing innovation and efficiency.
What then is a product?
So, what then is a product? A product is not a solution to a problem; it just enables the users to solve their problem. It can do this because it decouples the use-case from user-specific usages, and offers itself as a design pattern. The purpose of a product is the value-in-use, but if it tries to address the specifics of various usages it becomes a point solution. Or a monolithic mess that tries to be manypoint solutions.
Products are 'simple' machines. Consider the six simple machines of antiquity (lever, windlass, pulley, wedge, inclined plane, and screw): they offer mechanical advantage to you, the user. But you still have to do the work. Each of them encapsulates a use-case and offer themselves as (composable) design patterns. Combine an inclined plane and a screw: spiral staircase. A wedge and a screw makes a drill. A product is nothing more, and certainly nothing less, than a boost to a user's productivity with regards to some utility the user enjoys.
A Double Diamond Approach
We can use the Double Diamond design process model to implement the decoupling activity. The first 'diamond' discovers (divergent phase) and then defines (convergent phase) the problem space in the form of some use-case we can productise. The second 'diamond' then develops design patterns we can use to delivercomposable 'products' or methods.

Productisation transcends traditional product development, embedding itself as a core organisational strategy. Through the lens of the Double Diamond, it not only simplifies the complexity of innovation but also institutionalizes a dynamic framework for continuous improvement and market adaptation.
Double Diamond works in reverse, as well. Many people perceive the model as a process, where you discover-define-develop-deliver in that order. At Dairdux, we tend to see it as a map of different regions where the design 'process' can trace an erratic if not random journey. I just realised that you can work the Double Diamond backwards. Doing point solutions is fine, as long as you dedicate some effort to capitalising on them. By iteratively wresting something generalisable from delivered solutions, pointy or not, you develop patterns. As you progress, you can define a narrower set of use-cases, and, finally, discover a universal issue. This can help combat the human tendency to jump from the surface of the problem to conclusions about a 'solution' at the first sign of an opportunity.
Organisation from first principles
We can derive two principles from the heart of productisation: the principle of embodied microinnovation and the principle of recursive productisation.
Embodied microinnovation leverages productisation to explore and decompose the problem space into use cases and design patterns, converging on methods that a team can offer as a product. The microinnovation is 'the doing of new things or the doing of things in new ways' (as Schumpeter would have it) in the users' domain. And the users embody this microinnovation by adopting the usage of the product into their sociotechnical 'systems'. Specifically, into their sociotechnical practices.
Recursive productisation, in turn, applies the same approach within an organisation, creating a topology of teams where each offers itself as a product to other teams or units. This principle becomes recursive when you consider the market-facing productisation teams as the 'market' for internal platforms-as-products (any internal XaaS, really). The platform teams, then, is the 'market' for infrastructure-as-products. We think you should decompose organisational functions into products (and product teams). For instance, most business units nowadys need embedded data engineers and data scientists. So, someone should dedicate a team that offers to find and field eg. data engineers (talent sourcing as a platform-or-service). Incidentally, the business case for this product is the productivity gains for the business units. Recursive productisation reframes the governance and management layers of the organisation: they exist to boost the productivity of the teams doing business. If the managers are unable to conceive of the work they do as products for these teams, they aren't much use for the company, now are they? As the inimitable Drucker said, 'marketing and innovation are the only things that make money; everything else is cost'.
These principles highlight the strategic importance of productisation in driving organisational agility, fostering a culture of innovation, and ensuring market responsiveness.
Productisation in Data Mesh and Team Topologies
The concepts of platform teams in Data Mesh and Team Topologies perfectly embody the principle of recursive productisation by structuring organizations into modular, independent teams that offer themselves as products within a broader ecosystem. Data Mesh also describes teams that federate the governance of a data mesh. Team Topologies have their enabling teams. Same productisation story, different actors. Platform teams, as outlined, provide foundational services and capabilities that enable other teams (like the data product development teams of Data Mesh and the stream-aligned teams of Team Topologies) to focus on their direct, value-adding activities. This structure promotes efficiency, scalability, and innovation. Furthermore, any internal platform can be monetised by productising it for actors outside the company (in the revenue sense of productisation).
Data product development teams and stream-aligned teams, in turn, manifest the principle of embodied microinnovation by operating within this ecosystem to rapidly iterate, adapt, and innovate on their product offerings. These teams are designed to be closely aligned with the needs of the business or customer, enabling them to quickly respond to changes and incorporate feedback, thus driving continuous innovation at the micro level within the organization's broader strategic framework.
Data products themselves acquire 'product-hood' by decoupling the usage of data with its user-specific transformations and business semantics from the data-as-a-product.
Products are team-sized
While we are on the subject of Team Topologies, I figured that the best conclusion to this article is one of the shining diamonds in that book. Concepts like 'team cognitive load' and 'inverse Conway maneuver' indicate that products are team-sized. Everything worth doing in a company tends to require a team effort. And not just any team, but a cross-functional and multi-disciplinary team. If we see organisations as agent-based models (and we should), productisation teams are the primary agents. To spell it out clearly, this means teams that productisesome boost to some group of users, outside the company or inside.
Purpose. Mastery. Autonomy.
Productisation teams are the way to get things done. So, managers should see it as their jobs to enable (or boost, if you will) them to be movers and shakers. In the simple but powerful words of Pink's book Drivethis requires
- A cleanly scoped singular purpose (or objective, if we talk OKRs)
- The mastery to serve that purpose (skills, talents, and resources)
- And enough autonomy to work effectively
But what about cost control? The most effective way to achieve overall cost-effectiveness and protect the company's bottom line is not to minimise the costs to your own operation (leaving your people to do more with less) but to boost the productivity of other operations. I told you it was recursive, didn't I?
Appendix: why isn't EVERYONE already busy productising?
It's a pertinent question; I mean, Stafford Beer published his book Brain of the Firm in 1972. It's not like the idea of recursive patterns for organising an enterprise is new. What makes us think to that the time is now ripe for a paradigm shift? What has changed during the last 50 years? It's not about any specific change, but the accelerating rate of change. As Stefan Wendin says in the article embedded below: playing it safe is the riskiest move of all. Now more than ever. Betting that things will stay the same long enough for your products to pay dividends before they are obsoleted is a fool's gamble. Stop obsessing about your products and start productising! We bet that fear of obsolescence will be a powerful motivator.
Of course, there are other factors to consider. One of which is the inherent interest of managers and executives to retain the illusion of control. Incidentally,Dairdux just happens to be working on an article about this issue and the root problem of management heuristics, named "Innovate Without Trying: An Adoption-Centered Management Heuristic For Adaptive Growth".

Running Business-Critical Workflows on Fragile Point Solutions: When Shadow Data Work Becomes Best Practice
In this day and age of self-serve data platforms, microservices, and artificial intelligence, why do our Business units rely on Excel for running business-critical workflows? Because of functionally stupid governance—our sociotechnical systems are not cross-functionally aligned with the sociotechnical practices and needs of business operations. In plain English:
- Stop trying to build enterprise architecture, systems, and platforms
- The enterprise isn't doing business—it's a wholly abstract entity
- Operational units do business
- Start building products for them
Advice to the reader. This short article tries to help you discover a problem—the first step of a design process (specifically, of the Double Diamond design process model)
Shadow Data Work: Actual Best Practice In Business Operations
Doing business in today's fast-paced environement is challenging. It's a testament to the resilience and resourcefulness of the people that are doing data management and data work in our biz units that we are able to even stay in business. Our opportunity landscapes are fast becoming unmanageably volatile, uncertain, complex, and ambiguous (VUCA).
Our biz units fundamentally operate on urgency—adapting to new circumstances and getting things done at speed. They have to make do with the resources available to them within the agency bounded by their budgets, competences, mandates, and remits. They cannot wait for central functions to come out of their silos to resolve bottlenecks and blockers with robust and sustainable sociotechnical systems and practices. Biz units have to cope—play the cards dealt to them and work around structural problems to deal with their situation. This is suboptimal, for sure, but shadow data work done by citizen data managers and data workers is currently best practice—because that's as good as it gets, given the circumstances.
Shadow IT is a problem—and that problem is that IT isn't doing what it should
Central functions complain about Shadow IT and business operations being "too busy to improve". This indicates that the central functions have a pretty sizeable blind spot. Biz units do shadow work precisely because the central functions are not doing their jobs. On second thought, let's nuance this a bit. There's a more productive and actionable way to frame this.
Central functions are, in fact, doing their jobs. The problem is that the jobs they do try to serve a 'customer' that only exists in the abstract: the enterprise. The enterprise is just a faceless collective that obscures the various units trying to do their jobs—to the best of their existing abilities. To be of real service to the best interests of the enterprise as a collective, central functions must see the operational units as their customers—and build products for them.
Build products—not point solution spaghetti
Now, we mustn't jump straight into what Double Diamond calls solution space. If we do, and we start replacing enterprise systems with more or less tailor-made services for biz units, we risk rushing head-long into a monolithic mess of point solutions—the organisational version of what programmers call spaghetti code: a 'spaghetti' of projects and processes, if you will.
Designing, developing, and deploying data-driven products that are useful to our 'customers' and adoptable into their sociotechnical practices is no trivial thing. This goes double for useful and adoptable products that scale gracefully with the business as it grows. Well-designed products require well-organised productisation efforts.
- On the strategic level, you need to source productisation capabilities if you do not have them already
- On the operational level, you need actual cross-functional biz-data-tech teams that actually co-create self-services with and for the actual 'customers' that increases their productivity
- On the tactical level, you must organise, govern, and manage your productisation efforts
Delving deeper into making data work products
If this article makes sense to you, we can recommend a beefier article on designing, developing, and deploying products for data workers. It takes central data management as its starting point, rather than business units doing shadow data work—but it delves deeper into the fundamentals of making data work products.
Double Diamond is a productisation tool
Productisation capabilities are strategically important. Productisation transcends traditional product development, embedding itself as a core organisational strategy. If we expand slightly on that, it involves tools that help you productise. We argue that Double Diamond, a design process model, not only simplifies the complexity of innovation but also institutionalizes a dynamic framework for continuous improvement and market adaptation.

The first 'diamond' discovers (divergent phase) and then defines (convergent phase) the problem space in the form of some use-case we can productise. This article speaks mainly to problem discovery. The embedded article puts its focus on problem definition, the fundamentals of productisation. Additionally, it takes a few steps into the solution space, the second 'diamond'. The first step explores paths to 'solutions' by developing design patterns. The second, then, defines and deliver composable products.
Many people perceive the model as a linear process, where you discover-define-develop-deliver in that order. At Dairdux, we tend to see it as a map of different regions where the design 'process' can trace its erraticif not random journey.
Double Diamond works in reverse, as well. You can also work the Double Diamond backwards. Doing point solutions is fine, as long as you dedicate some effort to capitalising on them. By iteratively wresting something that is more generalisable from them, you develop patterns from delivered solutions, pointy or not. Eventually, you can define a set of use-cases, and, finally, discover the problem. This can help combat the very human tendency to jump from the surface of the problem to conclusions about a solution at the first sign of an opportunity for one.
Our interpretation of Double Diamond can be found in another article that tackles productisation in the abstract.

Domestication of AI
Our clinic yesterday on Mastering Business Domain Autonomomy in Data Managementspawned lots of productive discussions.
One of them was about AI agents co-existing with humans—which led to the expression domesticated AI. This opens up new ways of thinking about AI and ourselves. Can we—shouldwe—domesticate AI as we domesticated dogs and horses? Can we co-exist with AI in a way that respects both human and machine agency?
AI isn't human. However, lots of effort is going into designing AI agents to to be as human-like as possible in human contexts—such as self-driving cars driving like we expect humans to do or text-to-speech mimicking human errors, the extraneous 'filler' sounds we make, and personal idiosyncrasies. I'm not convinced that this is unconditionally positive. Expecting an AI agent to be human in more aspects than the specific interaction they were designed for (the Halo Effect) risks unnecessary, possibly counterproductive, anthropomorphism.
We already co-exist and cooperate with non-humans. We even co-habit with them. And have done so since we domesticated dogs and horses ages ago.
Context Setting: The Human-AI Conundrum
We imbue the learning machines we build with human-like qualities. When we explicitly design them to act human, the line between tool, companion, and colleague starts to blur. This creates ambiguity and ethical dilemmas. We argue that AI ethics is not about whether or not the AI agents lack morality—it's about our own ethics and our fears, human behaviour and bounded rationality.
When we cannot distinguish an AI agent from a human agent, we risk projecting our own biases on them. We risk misunderstanding their nature and capabilities, potentially leading to a Halo Effect of a misplaced anthropomorphism. We already anthropomorphise our pets—which are not human—which is not always beneficial to us or them. When we treat as human something which is not, we place unrealistic expectations on their behaviour—making decisions that can be dangerous for them or for us.
Problem Discovery: The Dual Doomsday Scenarios
The discussion we had raised some reflections on humanity's trajectory. We can frame this by two cinematic extremes: the apocalyptic rebellion of "The Terminator" and the complacent dystopia of "Wall-E". These scenarios serve as cautionary tales, highlighting the potential consequences of our current path—either losing control of our creations or abdicating our responsibilities to them. We argue that these stories reflect a deeper concern about how we view ourselves, our intelligence, and the ethical considerations of living alongside capable and autonomous beings of our creation.
Unpacking the Issue: Domestication vs. Anthropomorphism
Given co-existence with domesticated animals, we coined domesticated AI. This conceptual space allows AI, like domesticated animals, to exist in a symbiotic relationship with humans—serving specific roles without the pretense of being human. This perspective prompts a reevaluation of our goals in AI development, urging us to consider utility, relations, and coexistence over imitation.
AI designed to be human becomes a mirror that reflects our own insecurities, aspirations, and ethical quandaries. The push towards human-like AI challenges our understanding of intelligence, agency, and morality. It forces us to confront the limitations of our empathy and the depth of our stewardship. Are we seeking to create tools or colleagues? Servants, companions or idealised new beings?
Call to Action: Ethical Frameworks and Inclusive Dialogues
We are rushing headlong into an interesting future. But the path forward demands more than technological ingenuity—it requires ethical courage and philosophical clarity. Developing an ethical framework for AI
- that respects both human and machine agency and
- that fosters dialogue about the future we wish to build,
becomes imperative. Are we becoming better humans by developing AI? Domestication of AI poses questions about ourselves—the answers to which we might not like.

Data Management Isn't About Product Design—But It Should Be
EVERYTHING YOU THINK YOU KNOW ABOUT DATA MANAGEMENT IS... probably correct, actually.
Instead, we focus on management of the TO VALUE part of DATA TO VALUE—and how to productise it. Because productisation holds the key to more effective ways of working with data that allow you to scale as you grow.
A product offers a way of working—design products that offer new ways of doing data work
Companies need to turn data into value—boosting business decision-making and productivity by serving insights. That's why Data Management (DM) exists. Thing is, companies already have a vehicle for turning things into value and boosting productivity: products. Now, not all products are created equal—some being down-right shoddy—so we'll quickly qualify that to well-designed products.
While DM, for the most part, does exactly what it says on the tin—managing data as an asset—DM is no stranger to products. There's Self-Service Data plus Self-Service Analytics—it's downstream sibling, and Data as a Service. With Data Mesh came Data as a Product and Data Product. However, these concepts all try to make products out of the DATA part—not out of the TO VALUE part. Which isn't surprising, really—DM is about data, not product design. For most data managers, engineers, and scientists, product design and Design Thinking are unfamiliar or even foreign practices. This should change.
A well-designed product offers a way of doing things, of getting things done. Data makes for sub-par products. Instead, make products out of the ways data workers do their things—offer data workers new and effective ways of doing data work. That's what allows you to scale as you grow.
In a nutshell, we argue that some part of your company must start forming cross-functional teams that design, develop, and deploy data work products with and for company's data workers to stay competitive. It doesn't have to be the DM function—but it should be. Business units may know the data they have and use, but they tend not to know how to work their data effectively. They need help by autonomous data management teams to grow into Business Domains—and by that we really mean cross-functional biz-data-tech productisation teams.
Summary of the full story
The following bullets serve as both a table of content and a summary of the full story.
- TO VALUE centers on consumption of data work, transforming it into solutions, decisions, and actions
- DATA TO is a mindset that risks focussing data worker attention on merely managing their data instead of doing data work: 'consumables' useful to the consumers and usable in their bounded contexts
- Stop making products out of data and start co-creating self-services with and for data workers, offering them new ways of doing data work—because data work products are what enables Business Domains to form and to scale as they grow
- It takes cross-functional and autonomous data management teams to get shit done—it's the only way to breach the silos that's holding us back
- Data Management can save the day—the switch from data-driven to adoption-centered data work is spelled autonomous data management teams instituting new ways of doing data work
- You can only change culture by instituting new practices, not by decree or with motivational posters—the agents of change are productisation teams that institutionalise new behaviors and that change innovation from being a buzz-word into a practice
TO VALUE is about data work
If we zoom in on the data-to-value transformation, we see nothing but people busy doing their jobs—solving problems, making decisions, or taking actions for some outcome they are reaching for. All of them curate some sets of inputs and transform them in big or small ways using other inputs—for others to use as one of the inputs for their jobs. Data work is no different; it is only ever part of the input stage of some other work—which could be data work in its own right, serving some other purpose.
Data work exists to be consumed
Data work is a subset of knowledge work, distinguished by its dependency on sociotechnical systems and its methodical treatment of inputs. Science is data work—with strong validation and replication ambitions. Data is really just an abstraction for the sets of inputs that data workers curate and transform. That data is generally someone else's data work—taken as input. Data engineers do data work—consumed by data scientists doing their own data work to be consumed by others. DATA TO VALUE may be seen as a chain, but it is really a collection of individual data-to-value transformations.
Consumption is transformative
When you take our work as input for your work, you transform it. You make it yours—to serve the purpose of the work that you do. Consumption is the end of the line for any input—because whatever is going out is not the same. It has been transformed precisely because it now serves a new purpose—being input in some other bounded context.
The data-to-value transformation isn't really about what data workers do to their data. It's about digesting content from one bounded context and creating content that makes sense in another. Much like the 'knowledge work' you are currently reading—it tries very hard to make inputs from product design, multi-agent systems, and organisation theory make sense in the realm of data management.
The point of data work is VALUE-IN-USE for those who consume it
The fundamental VALUE part of work in general consists of the value-in-use people enjoy—enabled by the work of others. The TO VALUE part is workers explicitly boosting others with respect to the outcomes they are reaching for—specifically, boosting the producitivity of the 'reachers' with regards to their utility by improving their ways of working. It definitely helps if the 'booster' and the 'reachers' have a shared and agreed-upon understanding of each other—a trade language of sorts or a feedback loop that creates an interface between their respective bounded contexts.
To be frank, we claim that DATA TO VALUE goes in the wrong direction. The TO VALUE part starts with a use case. That determines the data work needed. This, in turn, determines what counts as data and what does not. In short, the data-to-value transformation becomes much more effective if you read it USE CASE TO DATA WORK TO DATA.
'Reachers' are more than consumers of data work
For the rest of the article, we'll be using reacher as the term for someone—be they persons, teams, or units—who consumes or uses anything, not just data work. While you may find it aggravating that people keep pushing new terms and concepts at you, there's a solid upside to switching from consumer to reacher.
Labelling people consumers puts our focus on what they are consuming and not on why they would ever do that. To put it boldly, thinking of them as 'consumers or users of data' is non-productive. It's bad semantics that block DM from being effective. When you think of them as reachers, you are forced to consider what they are reaching for. This mindset leads you to look at the ways in which they are doing things and at the outcomes they are reaching for. If you don't look, you will have trouble offering them new ways of doing things.
A mindset of DATA TO can block effective and scalable ways of doing data work
We realise the shock value of the next statement, but bear with us. We argue that a preoccupation with the DATA TO part of DATA TO VALUE is largely a blocker to scalability.
A DATA TO mindset steals the attention from productising new 'ways of working with data', meaning new ways of doing data work. It blinds us to the need for investing in productisation capabilities. The title for this article is nothing but an attempt at highlighting this blind spot. Which is important, because the prospects of doing data work successfully with a DATA TO mindset are not good.
The reality of doing data data work is... messy
Lots of people are very busy trying to turn data into value—furiously battling the volatile, uncertain, complex, and ambiguous (VUCA) reality of doing data work. Data workers and the reachers they serve are operating in different bounded contexts with their own semantics—making their interactions rife with misunderstanding and flush with frustration. It gets really messy when different bounded systems, architecture, infrastructure, and platform contexts clash—forcing data workers to carefully thread point solutions through the mess to get anything done. And they can unwittingly sabotage each other—one data worker committing changes to some shared input can easily break the workflows of others.
Turn the data work mess into a mesh of data work products
It's in everyone's interest that the reachers can get some value-in-use out of data work, and that data workers can do their jobs effectively. To be blunt, decomposing and refactoringthis mess into something that works cannot be championed on data worker level. It must be championed on manager level.
Someone has to organise, govern, and manage who does what parts of which specific transformations for whom. This is no small thing. We argue that productising ways of doing data work into a mesh of data work products is the shortest path to real improvement. Product Thinking means thinking Service Mesh and Data Mesh.
Data is like wheat—not iron
Many data workers are stuck in the DATA TO part of DATA TO VALUE precisely because they are disconnected from actual reachers. Instead, they do data work 'in a vacuum' without purpose-giving use cases—the absence of which reduces them to mere custodians of data.
Data is commonly managed as an asset or a resource to be refined. Like iron—a natural resource that we humans can find, mine, and extract. We blithely assume that there is a hierarchy of value-adding steps that elevates raw data to source data to information to knowledge to understanding, wisdom, or truth. This belief is a dangerous fallacy, because data is not like iron. We cannot work data as if it were a natural resource—it's wholly man-made, crafted from scratch to serve human purposes.
Consider wheat cultivation
Wheat conjures up images of bread-baking and pasta-making. But wheat is useful in all its forms—not just when milled to various types of flour. The same is true for data. Sprouted wheat grains can used as-is for salads, sandwiches, or health drinks. The grains can be boiled for salads, soups, or stews. They can be shredded or flaked for cereals or cracked for bulgur. A lot of the wheat produced go straight to livestock feed. Wheat husks can be used as filler material in plastics or for biofuel. Wheat straw can be used as construction material (straw bales) or for making paper or cardboard. Or it can be used as mulch and even a substrate for growing mushrooms.
Think of data work as wheat work. At no point in its life cycle can wheat be considered raw. Furthermore, every step of every way of processing what is productised. And new ways of doing wheat work can be productised—even new ways of growing new type of wheat.
The data-to-value chain is a distracting abstraction
Above, we urged you to view data work as a consumable. Taken seriously, it decomposes the data-to-value chain into individual TO VALUE transformations—distinct and discrete interfaces and feedback loops with actual data workers doing actual data work on one side and actual reachers actually consuming their work on the other. Data is just an abstraction for the input stage of data work which is the input stage of consumption. Data work transforms data to a consumable. Consumption transforms data work to something that enables value-in-use in another bounded context—solving problems, making decisions, taking actions, such as doing business or other data work.
There is no data-to-value chain. There is just an organically grown array of individual 'links' coupled into a confusing weave of point solutions. And that weave doesn't allow for scaling as you grow.
Stop making products out of data—start offering new ways of doing data work
A well-designed product offers a way of doing things, of getting things done. In design-speak, it affordsusages. Productisation, then, looks at what people are doing and how they do their things to decouple a general use-case from those doings. The point is to offer the people a new way of doing things or even new things to do.
A product should not try to solve the problem for the problem-havers. That's what a point solution does, and that doesn't scale. If it tries to solve many problems for many reachers, it becomes a monolithic mess of point solutions.
Instead, it should be the means by which they solve the problem themselves—a design pattern that affords usages. The reachers still have to put in the actual work of doing the new things or doing old things in new ways.
"Hey! We could probably make money off of this!"
Productisation is the act or process of turning ideas, activities, and things into 'marketable' products. Put differently, productisationis what product designers and developers do.
If we go by Schumpeter's definition of innovation as 'the doing of new things or the doing of things in new ways', productisation is innovation in the second sense. Productisation makes a product out of some part of some people's ways of doing things and offers it to them—and they adopt it as a practice if they enjoy the new way of doing their things. The adopters' value-in-use is the boost to their productivity with regards to some utility they enjoy. Hence, we claim that adoption is the quantum of innovation, because adoption of product usages boosts the productivity of the adopters.
Think of products in terms of simple machines
A fundamental analogy for understanding products is simple machines. Consider the six simple machines of antiquity: lever, wheel-and-axle, pulley, wedge, inclined plane, and screw. From a physics perspective, they are force amplifiers that offer mechanical advantage to you, the user. They boost you by distributing the work you need to do over a distance, reducing the force needed. But you still have to do the work.
From a design perspective, they afford you different usages. Consider the wedge, mankind's oldest tool: a more effective fingernail or tooth. The usages it affords include the following.
- Splitting or cleaving things—as an axe (technically, it's a hand axe until we add a lever)
- Cutting things—as a knife. If you serrate the edge you get a saw (the teeth are tiny wedges).
- Puncturing things—as a needle (small) or a spear (big)
- Prying things apart—as a movable inclined plane. You could use a knife, but you risk destroying the edge—effectively turning the knife into a prybar.
- Digging—as a spade (without a handle)
From a product perspective, simple machines offer new ways of working.
Simple machines are composable design patterns
The wedge, as any simple machine, encapsulates a general use case and offers a composable design patternthat affords various user-specific usages.
The genius of simple machines is that they are useful and usable on their own while also being composable—capable of being composed into more complex machines that affords other usages. Combine an inclined plane and a screw, and you get a spiral staircase. A wheel-and-axle and two levers make a wheelbarrow. One or more pulleys on a lever forms a crane. A screw with a wedge is a drill. A wedge with a lever, an axe, a prybar, or a shovel, depending on composition.
But simple machines—or, indeed, any product, don't create themselves. Someone has to take responsibilty for designing, developing, and deploying them.
The Principle of 'Data Work Product Ownership'
We argue that data managers should be accountable, if not responsible, for creating data work products for the data workers that consume 'managed data'. To put it provocatively, merely managing data is useless. We'll quickly add that useless does not mean worthless. We are saying that what really creates value for data workers is stuff that makes them more effective as data workers.
That means being able to do actual data work for their reachers—not wasting time and effort on battling upstream data managers and data engineers for the inputs they need. In short, data managers should take ownership of designing, developing, and deploying data work products as their job. Even if they don't personally participate in productisation efforts, someone has to enable and manage those efforts.
The same goes for Business Domains (Bizdoms for short). Data managers in Bizdoms should take ownership of designing, developing, and deploying their own data work products for their own data workers. The business case is that that helps the Bizdom's data workers to better serve reachers in the Bizdom or reachers downstream from it, such as actual paying customers.
Data work product ownership requires investing in productisation capabilities
A product is the result of a productisation effort. Well-designed products are results of well-organised productisation efforts. It's the productisation capabilities of DM and Bizdoms that determine whether or not their ways of doing data work are effective and enable you to scale as you grow.
And that is structural capital. Investing in human capital is never a bad thing—talents, skills, and competences are necessary ingredients for productivity. But it's not nearly enough.
Focussing myopically on human capital and hoping that these individuals will save your business by virtue of being masters of their crafts makes the mistake of forgetting a tiny little thing: the whole matter of organising them into concern-separated productisation teams. Teams with high cohesion and low coupling to other teams or units—teams that can operate with purpose, mastery, and autonomy. Before we delve into this, let's talk about what productisation teams do.
Data work products offer new ways of doing data work and enable Business Domains to form and to scale as they grow
In practice, productising ways of doing data work means co-creating self-services with and for data workers so they can do their data work more productively. This is a mouthful, so let's call those self-services data work products. For such products, well-designed means useful to data workers and adoptable into their sociotechnical practices.
A data work product mirrors the interface in Team Topologies (TT) between platform teams and stream-aligned teams. TT terms that a X-as-a-Service interface. It means the same thing: a productivity-boosting convenience to the reachers who consume it. The interface in Data Mesh between its platform teams and the data product dev teams follows the same formula. We'd argue that its self-serve data platform is nothing but data work products. Additionally, the data products of Data Mesh are data work products in their own right.
Well-designed products hinge on good semantics
Products made out of data are the most basic form of products: goods. The business logic for goods is offering at low cost and effort to the reachers something that they already know exactly how to use in their operations. The producer can pay full attention to producing their goods because they do not need to think about why the reachers need them or how they are going to use them.
As soon as the reachers have doubts and questions about what they need—and, therefore, what to buy and how to use it—goods logic fails as a business model. That is why well-designed products must look to their ways of doing things and design something that makes sense as a usage in their operations and to the people in operations.
Confused by product, good, service, and self-service? You have good reason!
We use product because service is a semantic warzone. For instance, TT uses X-as-a-Service for what is really a self-service—the polar opposite of service. Even funnier is that self-service actually captures the essence of product—which is why we use it to define data work product. Also, a service—while being a type of 'marketable' product—can have a market of a single consumer and still be a viable service. This is not a good mindset for data work products.
There is a method to the madness of arguing semantics. We are trying to develop what Domain-Driven Design calls a 'ubiquitous language' in shaping our 'domain model' of adoption-centered management of the sociotechnics of Data & AI.
The data products of Data Mesh are data work products
Data Mesh data products offer new ways of working. While they contain data, that is not why data workers adopt them into their practices. Data workers adopt them because data products are composable simple machines.
We'd argue that developing data products as they appear in Data Mesh manifests as "co-creating self-services with and for data workers so they can do their data work more productively". The genius of Data Mesh has little to do with actual data. It lies in how the data product developers productise data work. Simply put, a data product decouples data from context-specific semantics and usages—thereby becoming bridges between bounded contexts.
In the abstract, they apply Design Thinking—and design patterns in particular—to data work. They decouple data work use cases from the messiness of the actual data usages of data workers, meaning the specific ways in which they curate and transform their sets of inputs.
To elaborate, data product developers decompose data work into concern-separating use cases much in the same way programmers refactor their code. These use cases have high internal cohesion and low coupling to other use cases—and are distributed into a mesh network topology. If we use the language of Double Diamond, a design process model, we can say that this organises the problem space of data work—which minimises friction and maximises scalability.
Then they implement data products as composable design patterns to serve these data work use cases. This organises the solution space of data work. Note that data products—and design patterns in general—afford usages; they are not solutions to problems. They offer themselves as self-services to data workers who consume them as a means for them to solve their own problems—which removes bottlenecks.
For individual data workers, data products are a net bonus. The upside is that each data worker can more easily self-serve some of the inputs they need, offering more effective ways of doing data work. The downside is that the data product pushes any data transformation that is specific to a data worker into their data work. Which is actually fair—everyone should own the tasks that matters only to them.
The upside for DM in general—and DM in Bizdoms in particular—is that composable data products allows for scaling with growth.
It takes a cross-functional and autonomous team to get shit done
Co-creating self-services with and for data workers takes the effort of a cross-functional biz-data-tech data work productisation team. That's also a mouthful, so let's call such teams prod teams for short. We'll also call them autonomous data management teams so we can sneak the concept into DM and stealth-transform DM as a practice. Importantly, everything TT says about teams—platform teams and stream-aligned teams in particular—is valid for prod teams. Just replace the XaaS interface with data worker self-services or products in your mind. In fact, we'd argue that TT's XaaS interface manifests precisely what we mean with a data work product.
A team requires purpose, mastery, and autonomy to be effective
Purpose is a clear and crisp sense of direction—giving the team a shared and agreed-upon understanding of what they are supposed to be doing and where they are going
Autonomy is the team's degrees of freedom—the extent to which the team can operate without being bottlenecked or blocked by dependencies
Mastery is about the capabilities needed to do a good job. Co-creating self-services with and for data workers masterfully requires diversity in talents, competences, and skills (and resources). The authors use biz-data-tech as a shorthand for the following breakdown of the required areas of expertise.
- Business development and organisational development
- Product or service design and user UX-UI
- Data engineering, data science, business intelligence, machine learning, or artificial intelligence—depending on which type of data work is being productised and what the data workers' consumers are expecting
- Platform engineering, including the tech stack
We use cross-functional instead of multidisciplinary because most companies are organised by function, not domain. If your company is organised by domain—well done! Please read cross-functional as multidisciplinary or even transdisciplinary instead. A prod team has to be cross-functional to have chance of doing their job masterfully. It also needs enough autonomy to be able to operate without bottlenecks.
You can only breach the silos by forming cross-functional and autonomous teams
Anyone who has ever tried to get shit done in a functional organisation is painfully aware of the frustrating insularity of silos. The fact that we must explicitly qualify prod teams as cross-functional and autonomous points to a fundamental anti-pattern in companies organised by function. Functional organisations devolve into silos by design.
A normal business unit or area is nowhere near to being a Bizdom—precisely because they are a function. Frankly, this spells hardships for the very concept of a Business Domain. The reason is simple. A Bizdom operates like a big prod team. It has to be cross-functional and autonomous to be effective.
A Business Domain starts as a prod team
For companies organised by function, the path to effective and scalable ways of doing data work will, unfortunately, be arduous. Fortunately, the path is actionable—because a single prod team is a net bonus. In precisely the same way that a data mesh can grow from the initial data products, a prod team can grow into several and then into a business domain. And that can spawn others, building momentum from the compounding effects of adding net bonuses one at a time.
Data Management can save the day—by switching from data-driven to adoption-centered data work
Data managers have the power to boost the productivity, and even transform the culture, of the entire company simply by forming and managing autonomous data management teams, distributed and embedded as prod teams in business units.
Changing the culture of an organisation is not difficult—it just takes time. Organisational culture is simply the consequences of operational practices. Practices institutionalise organisational behaviours. New ways of working engenders new practices—which begets new organisational behaviours to replace the old ones.
Being data-driven is not nearly enough. It is adoption of data work products that drives business—not data. So, take data work seriously. If you don't, your company will never be Data-AI-Ready. Inevitably, you will be out-competed and obsoleted by companies that do. The shortest path to success is adoption-centered management of data work that operates autonomously in and with the business units.
Get out there and start productising the work that data workers do! Form your first autonomous data management teams with the express purpose to productise better ways of working.
Data Management can be the catalyst for transformation
In environments cursed by VUCA opportunity landscapes and the bewildering sociotechnics of Data & AI, Data Management can stand tall. Not just as a guardian of data integrity, but as the the catalyst for organizational innovation and growth. The data to value transformation has often been misconstrued as a linear process from source data to business-driving insights. We argue that it is anything but. It is a non-linear and dynamic journey of exploring new ways of working, where the real treasure lies not in the data itself, but in how we leverage it to enhance decision-making, boost productivity, and ultimately foster business agility.
DM has largely been pigeonholed into a custodial role, preoccupied with safeguarding data as an asset. Now, imagine the transformative potential if DM shifts its focus from merely managing data to actively productising data work. By forging cross-functional, autonomous teams tasked with creating data work products, DM can become a shaper of business—growing Bizdoms that are not merely data-informed but also adaptive and scalable—with regards to the operational needs of their data workers.
It's time for DM functions to evolve beyond traditional confines and embrace the principles of product design and Design Thinking
Evolution requires a shift towards adoption-centered management, where the measure of success is not the volume of data curated but the effectiveness and scalability of the products provided to the data workers. Adopting this mindset doesn’t merely enhance DM—it propels entire organisations forward, enabling them to navigate the complexities of the modern business environment with greater agility and foresight.
The formation of autonomous data management teams, deeply embedded within business units, opens the doors to the future. These teams, productising new way of doing data work, not only enable business units to create value for themselves and the company—they prime the organization for continuous innovation and competitive advantage.
Being data-driven is commendable. Ultimately, however, it is the adoption of well-designed data work products that propels businesses forward. The time to act is now. DM has the opportunity, the responsibility, and the power to redefine itself as the cornerstone of a modern, agile, and innovative enterprise. Start by forming your first cross-functional productization team, and embark on transforming data work, driving business growth.
You can only change culture by instituting new practices
Autonomous data management teams that design, develop, and deploy data work products is not a mere shift in operational focus. They herald a choice of evolutionary paths. Changing the fabric of organizational culture may be a daunting prospect—but that happens automatically and naturally as new ways of doing data work take root. You cannot change organisational cultural by decree or with motivational posters. Productisation teams institutionalise new behaviors and change innovation from being a buzz-word into a practice.
Don't wait for the future to dictate your actions! Let DM lead the way in crafting a future where data work is a catalyst for innovation, value creation, and enduring success.